From Bottlenecks to Balance: Dynamic Skew Join Fixes in Spark

When working with large datasets in Spark, joins are a common operation. But what happens when data distribution isn’t uniform? Let’s dive into a real-world scenario to understand why dynamic skew join optimization is not just useful, but often essential.
The Problem Setup
Assume we have two large tables and we’re trying to join them using the following Spark SQL:
SELECT *
FROM large_table_one
JOIN large_table_two
ON large_table_one.key = large_table_two.key
Or using the equivalent Spark DataFrame API:
df1.join(df2, df1.key == df2.key, "inner").filter("value == 'random'")
Since both tables are large, we expect a sort-merge join to occur. When you run the job and inspect the execution plan, you’ll notice Exchange nodes — one for each table — indicating shuffle operations. Each table is being partitioned by the join key.
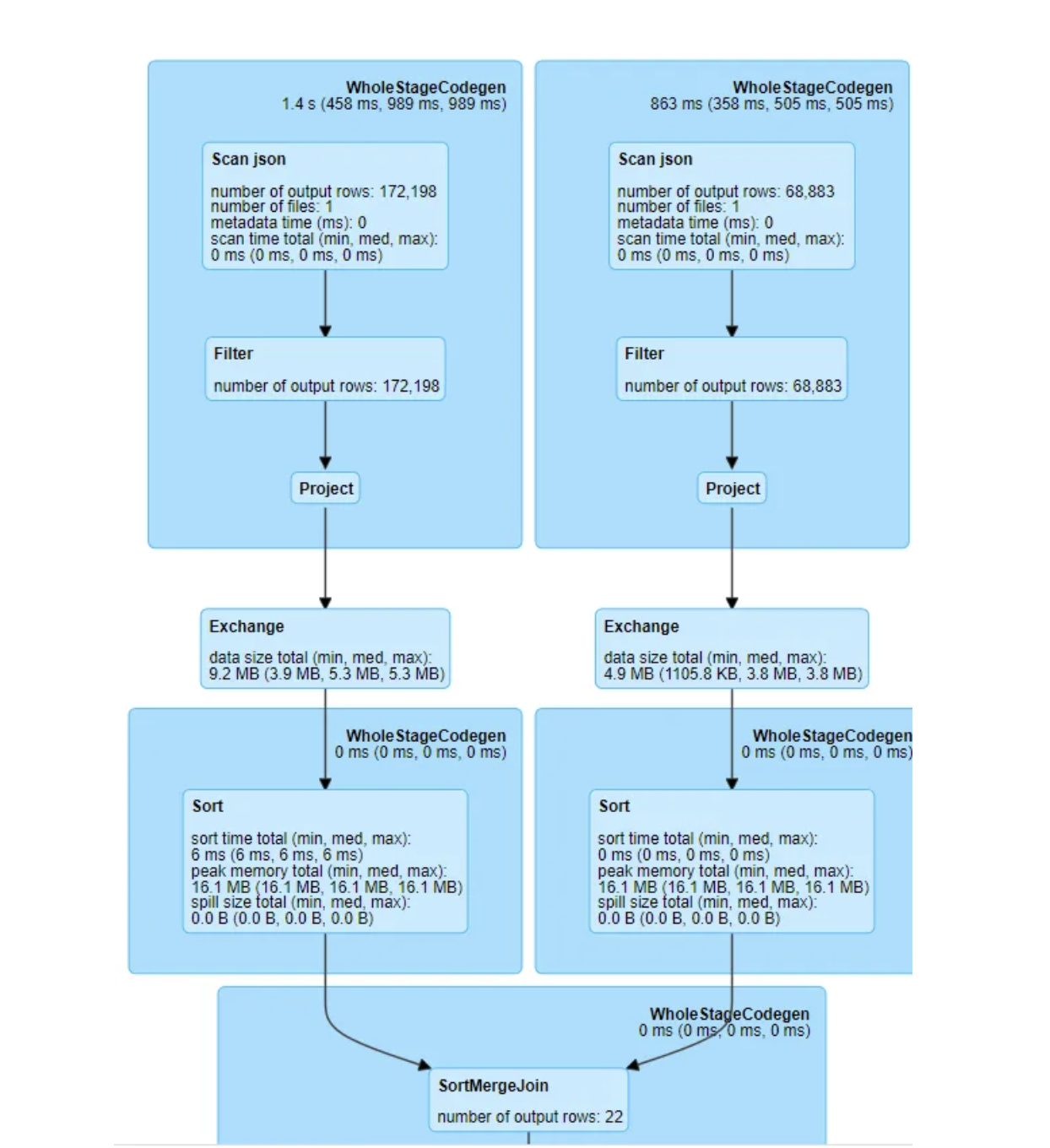
Shuffling and Partitioning
Let’s dig deeper.
Assume large_table_one initially has two partitions.
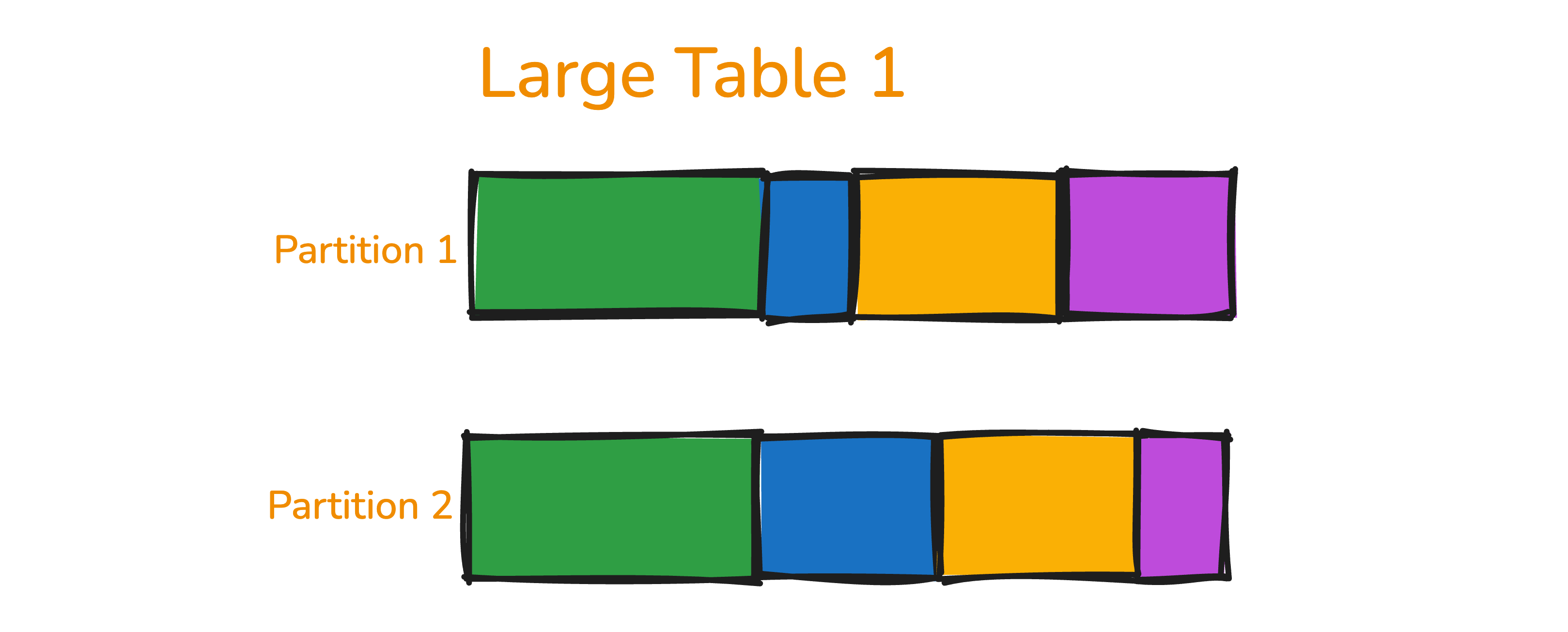
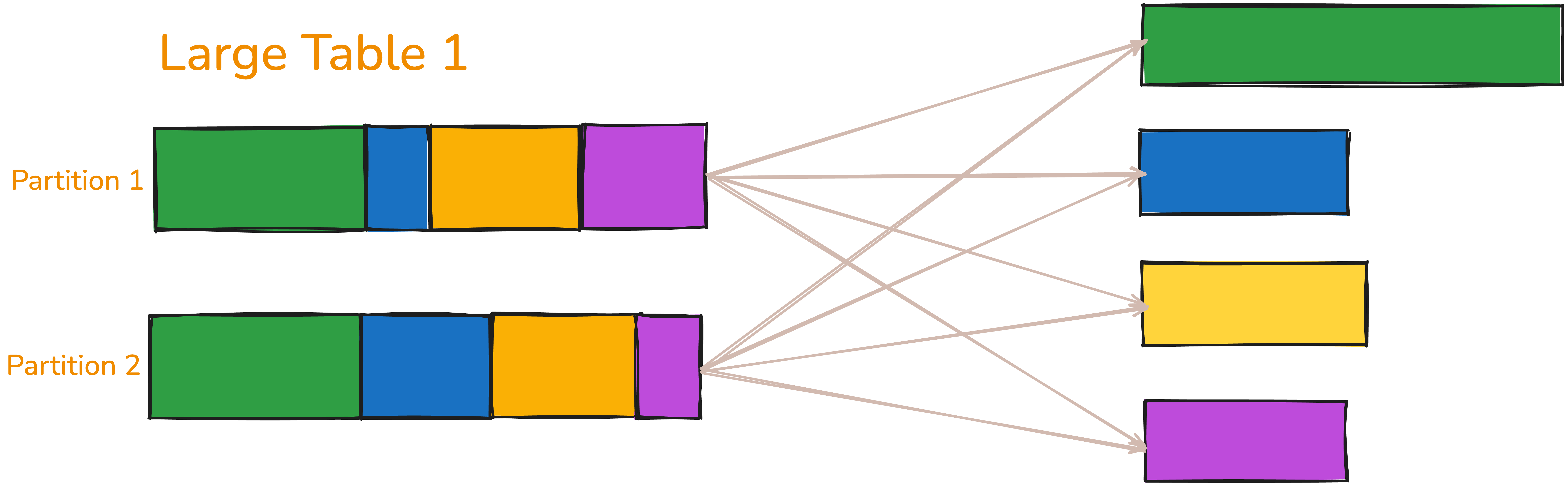
Each partition contains rows with different join keys, represented using different colors (for visualization purposes). After shuffling, Spark redistributes the data such that each partition contains rows with the same join key. This repartitioning by join key is the primary purpose of the shuffle, resulting in:
You’ll see the same happen to large_table_two — it’s shuffled in a similar way so that corresponding keys are aligned for joining.
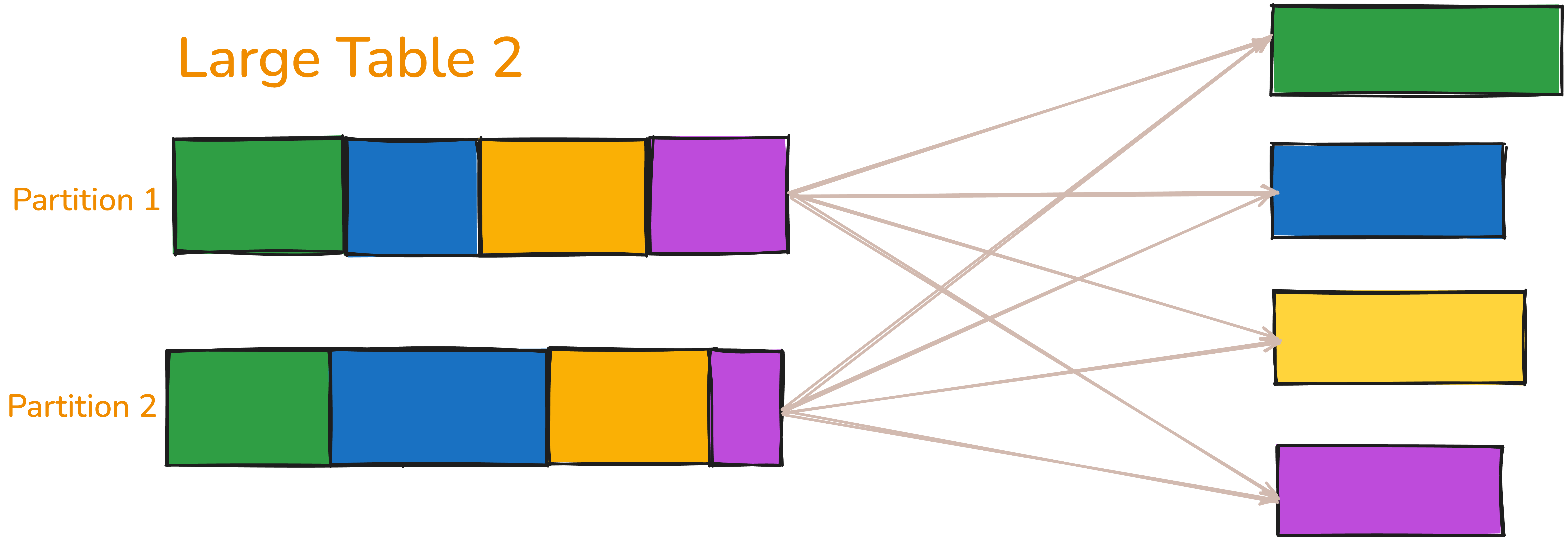
Now that both tables are partitioned by key, Spark proceeds with the sort-merge join. If we have four partitions, we’ll get four tasks — each responsible for sorting and merging data for a specific key.

But Here’s the Catch…
At a glance, this looks fine. But look closely — one of the partitions (the one with green-colored data) is much larger than the others. This means the task handling that partition has a heavier load.
Let’s say you configured your Spark executor to allocate 4GB of RAM per task. That works well for all other partitions, but the green partition needs more memory to complete the sort/merge. This becomes a problem.
So, Should We Increase Memory?
Sure, you could increase the memory to handle the skewed join. But here’s why that’s a bad idea:
1. Memory Wastage
Most of your joins work fine with 4GB. Only one task is failing due to skew. But Spark doesn’t allow configuring memory at task-level granularity, so you’d end up increasing memory for the entire application, leading to wastage.
2. Not a Long-Term Fix
Let’s say today the skewed partition needs 6GB. You bump up the memory and move on. But next week the data changes — now it needs 8GB. Your app fails again. You fix it again. This cycle repeats. It’s not scalable or reliable.
Enter Adaptive Query Execution (AQE)
Spark’s Adaptive Query Execution (AQE) provides an elegant solution. Enable AQE and skew join optimization with the following configurations:
spark.sql.adaptive.enabled = true
spark.sql.adaptive.skewjoin.enabled = true
Version Note: AQE was introduced in Spark 3.0 and has been improved in subsequent versions. Make sure you’re running Spark 3.0 or later to use these features.
Now, Spark monitors the actual size of shuffled partitions at runtime. If it detects skew, it dynamically rewrites the execution plan on the fly.
What Happens Under the Hood?
Let’s revisit our example. Initially, there are 4 shuffle partitions, hence 4 tasks. One of them is skewed (green). That task struggles and runs longer, maybe even fails.
But since AQE is enabled, Spark notices the skew and takes the following actions:
- Splits the skewed partition into two or more smaller partitions.
- Duplicates the matching partition from the other side of the join (so each split can be joined independently).
As a result, we now have 5 tasks instead of 4. But the load is evenly distributed, and tasks finish faster and more reliably.
Fine-Tuning Skew Detection
Two important configurations let you control when Spark considers a partition to be skewed:
# default values
spark.sql.adaptive.skewjoin.skewedPartitionFactor = 5
spark.sql.adaptive.skewjoin.skewedPartitionThresholdInBytes = 256MB
Let’s break these down:
skewedPartitionFactor = 5: Spark compares the size of each partition with the median partition size. If a partition is 5 times larger than the median, it is a candidate for being skewed.skewedPartitionThresholdInBytes = 256MB: This is the minimum size threshold in bytes. Even if the partition is 5x larger, Spark will not treat it as skewed unless it’s also larger than 256MB.
Remember, Spark AQE will initiate the split if and only if both thresholds are broken. This dual-check prevents unnecessary rewrites and ensures only truly skewed partitions are targeted.
You can fine-tune these values depending on the scale and distribution of your data. For example, on massive datasets, you might want to raise the threshold slightly to avoid over-optimization. Conversely, for smaller datasets where a 200MB skew might still cause trouble, you might lower the threshold.
Final Thoughts
Dynamic skew join optimization isn’t just a performance tweak — it’s a fundamental shift in how Spark handles real-world data.
Instead of throwing more memory at the problem or endlessly tuning partition sizes, Spark with Adaptive Query Execution (AQE) becomes intelligent enough to adapt on the fly. It detects issues as they happen and rewrites plans accordingly — no manual babysitting required.
Here’s why it matters:
- 🧠 Smarter Execution: Detects and splits skewed partitions dynamically.
- 🚀 Faster Jobs: No more stragglers slowing everything down.
- 💸 Cost-Efficient: Avoids blanket over-provisioning of resources.
- 🔁 Future-Proof: Adapts to changing data shapes over time.
So next time you’re debugging a painfully slow Spark join — take a step back. Maybe the fix isn’t another config. Maybe it’s time to let Spark adapt.
Enable AQE, let it handle the skew, and focus on what actually matters — building pipelines that scale.
Lastly, thank you for reading this post. For more awesome posts, you can explore my other articles here, and follow me on Github — amarlearning.
#spark #big data #optimization #data engineering #performance #spark-joins