Deep Dive into Spark Jobs and Stages
When working with large-scale data processing using Apache Spark, understanding how jobs and stages work is crucial to optimizing performance. This blog is for those who already have some experience with Spark and want to dig deeper into the internal mechanics of jobs and stages.
Spark Transformations and Actions
In Spark, operations are classified into two main categories: Transformations and Actions.
- Transformations: These operations do not trigger execution but define a new dataset from an existing one. Transformations are further categorized into:
- Narrow Dependency: Performed in parallel on data partitions. Examples include
select(),filter(),withColumn(),drop(). These transformations are efficient as they do not involve shuffling. - Wide Dependency: Require data from multiple partitions to be grouped or aggregated, leading to shuffle operations. Examples include
groupBy(),join(),cube(),rollup(),agg(), andrepartition(). These operations can be costly due to data movement between nodes.
- Narrow Dependency: Performed in parallel on data partitions. Examples include
- Actions: These trigger the execution of the transformations and produce an output. Examples include
read(),write(),collect(),take(), andcount(). Each action triggers a separate job in Spark.
Examples
Let’s look at some code examples to understand these concepts better:
Example 1: Narrow Transformations
df = spark.createDataFrame([
(1, "A", 100),
(2, "B", 200),
(3, "A", 300),
(4, "B", 400)
], ["id", "category", "value"])
df_filtered = df.filter(col("value") > 200)
df_mapped = df.withColumn("ratio", col("value") / 100)
Example 2: Wide Transformations
# These operations require data shuffle between partitions
df_grouped = df.groupBy("category").agg(sum("value")) # Wide: requires shuffle/sort
df_windowed = df.withColumn(
"running_total",
sum("value").over(Window.partitionBy("category").orderBy("value"))
)
Example 3: Understanding Jobs and Stages
# Action 1: Reading data
df = spark.read.parquet('/path/to/parquet')
# Multiple transformations leading to multiple stages
result = (df
.repartition(numPartitions=2) # Wide ransformation (shuffle)
.where("age > 25") # Narrow transformation
.select("name", "country") # Narrow transformation
.groupBy("country") # Wide transformation (shuffle)
.count() # Action 2: triggers job execution
)
Jobs and Stages
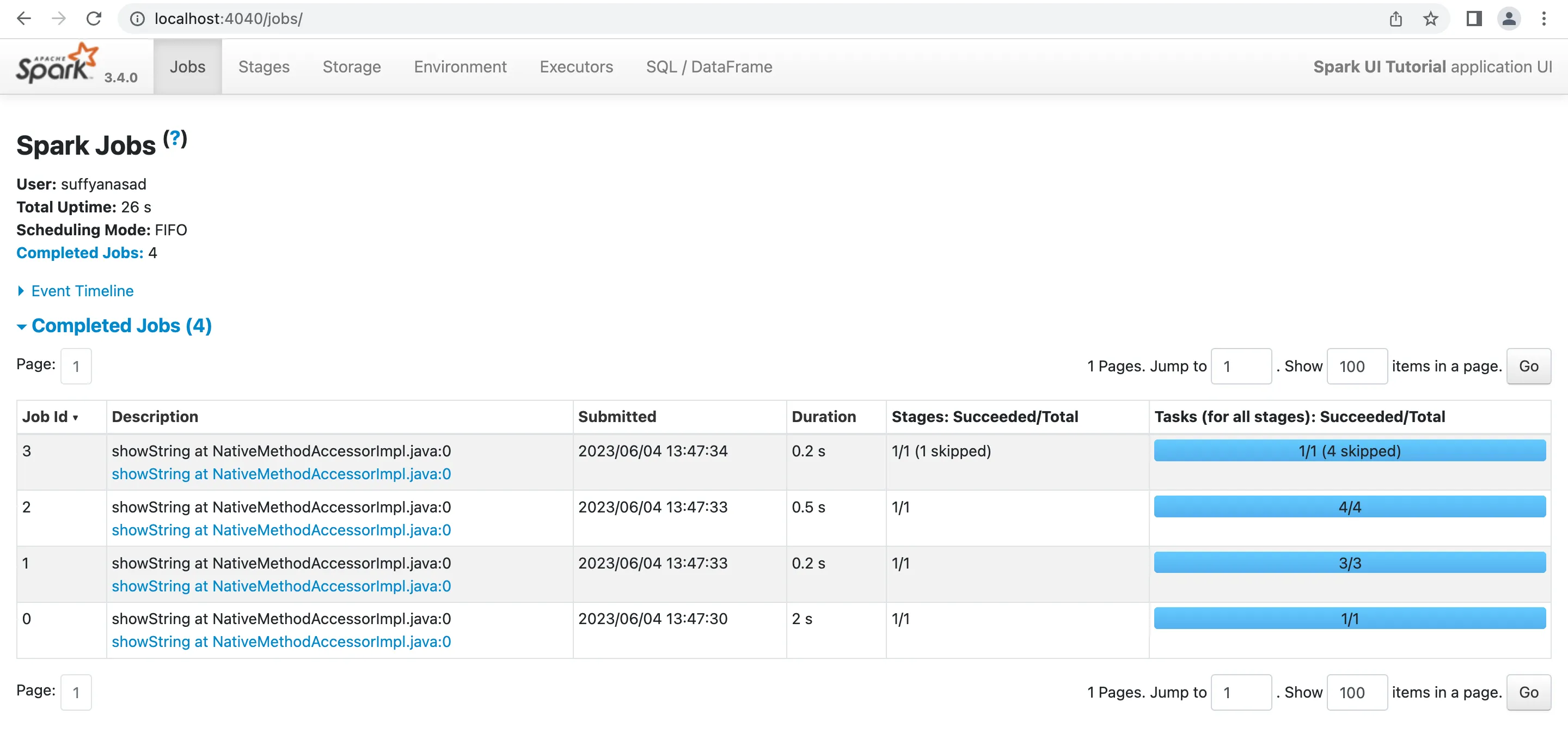
Spark creates a job for each action called. A single job can contain a series of actions, but Spark will optimize these actions into a single logical plan before executing it. The logical plan is then broken into physical stages based on wide dependencies. If no wide dependency exists, the entire logical plan results in a single stage.
The key to understanding stages is recognizing that each wide dependency (like a shuffle) creates a boundary between stages. Therefore, if a Spark job has N wide dependencies, the logical plan will have N+1 stages. Data movement between stages occurs via shuffle and sort operations.
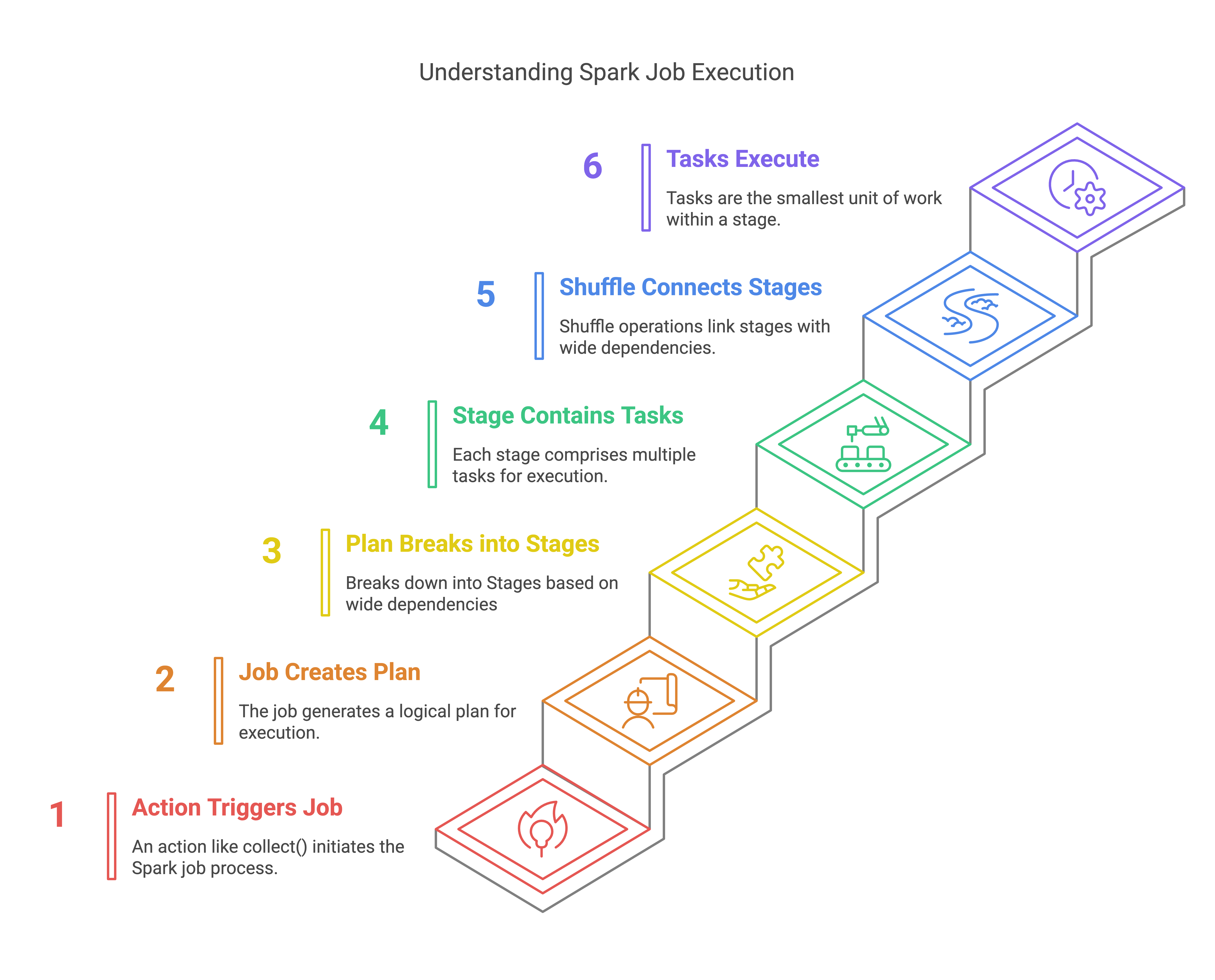
To better understand how Spark organizes jobs and stages, let’s break down the flow:
- Action (e.g., write(), collect()) → Triggers a Job
- Job → Creates a Logical Plan
- Logical Plan → Breaks down into Stages based on wide dependencies
- Stage → Contains multiple Tasks, one per partition
- Shuffle/Sort → Connects Stages when wide dependencies are present
- Tasks → Smallest unit of execution within each stage
Tasks and Parallelism
Inside each stage, Spark divides the workload into multiple tasks, with each task processing a single partition. These tasks are executed in parallel by the Spark executors. The number of tasks within a stage equals the number of input partitions.
Tasks are the smallest unit of execution within a Spark job. The Spark driver assigns these tasks to executors and monitors their progress. It is essential to balance the number of tasks and partition sizes to avoid performance bottlenecks.
For tips on optimizing Spark partitions for performance, read more here.
Conclusion
Understanding Spark’s execution model - particularly how jobs break into stages at shuffle boundaries - is fundamental to writing efficient Spark applications. Key takeaways:
- Actions trigger jobs, not transformations
- Wide transformations create stage boundaries due to data shuffling
- Minimize shuffles when possible by reducing wide transformations
- Monitor your job’s stages through Spark UI to identify performance bottlenecks
Lastly, thank you for reading this post. For more awesome posts, you can explore my other articles here, and follow me on Github — amarlearning.
#apache-spark #big data #data-processing #performance-optimization #distributed-computing #spark-optimization