Balancing the RUM Conjecture: Navigating Database Trade-Offs

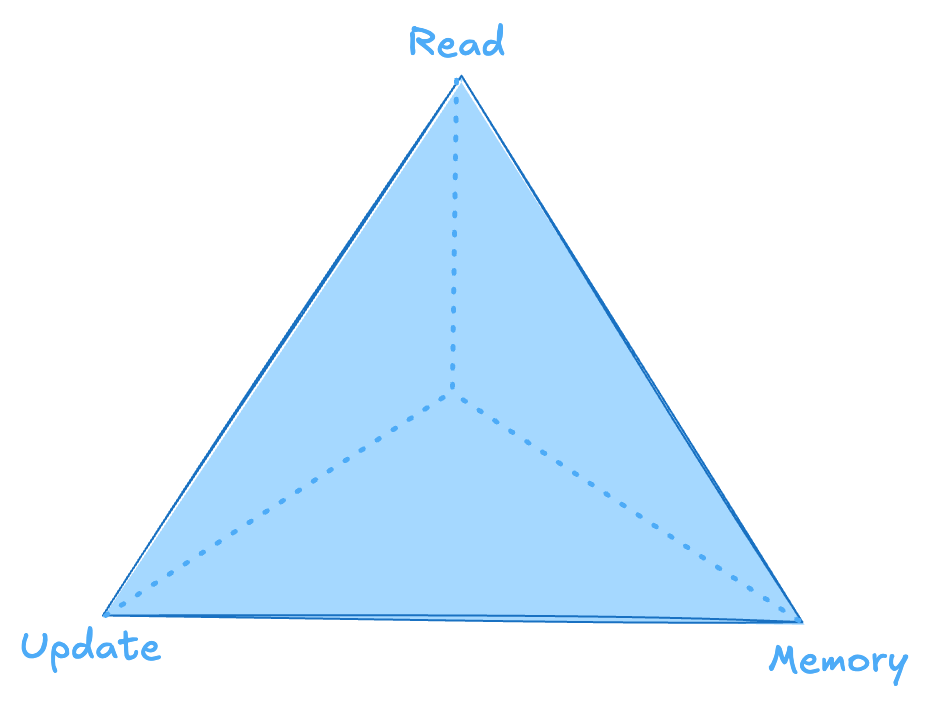
When designing databases, there’s a constant balancing act among three main factors:
- Read times
- Update cost
- Memory/storage overhead
The RUM Conjecture suggests that optimizing any two of these factors will negatively impact the third. Essentially, you can only choose two out of the three to prioritize in any design.
Example: Log-Structured Databases
Consider a log-structured database:
- Update-optimized: Records are appended at the end of the file, allowing efficient updates.
- Low memory/storage overhead: There’s no additional indexing, saving on storage.
- Trade-off on reads: Without indexes, lookups become slower, negatively impacting read times.
This trade-off forms a triangular relationship among read efficiency, update costs, and storage overhead.
Visualizing RUM
Databases are often optimized around specific workflows, focusing on either read, write, or storage efficiencies:
- Read-Optimized
- These databases are designed to minimize read latency, often by increasing storage and write costs (sometimes both).
- Examples: B-trees, hash-based indexes, tries, and skiplists.
- Trade-off: To provide fast read times, data is often duplicated or structured in ways that require more storage or additional writes.
- Write-Optimized
- These systems prioritize efficient writes, typically by reducing write complexity and minimizing disk overhead.
- Examples: Log-Structured Merge (LSM) trees, partitioned B-trees, and LA/FO trees.
- Trade-off: While these structures offer low-latency writes, they generally sacrifice read speed and increase memory or storage requirements.
- Storage-Optimized
- These databases aim to conserve storage space by trading off write costs (through compression) or read performance (by requiring multiple lookups).
- Examples: Bloom filters, count-min sketches, and sparse indexes.
- Trade-off: Although these structures are space-efficient, they often compromise on write efficiency or retrieval speed.
Beyond the RUM Corners: Adaptive Access Methods
Some database structures are designed to adapt dynamically, balancing the RUM trade-offs based on access patterns:
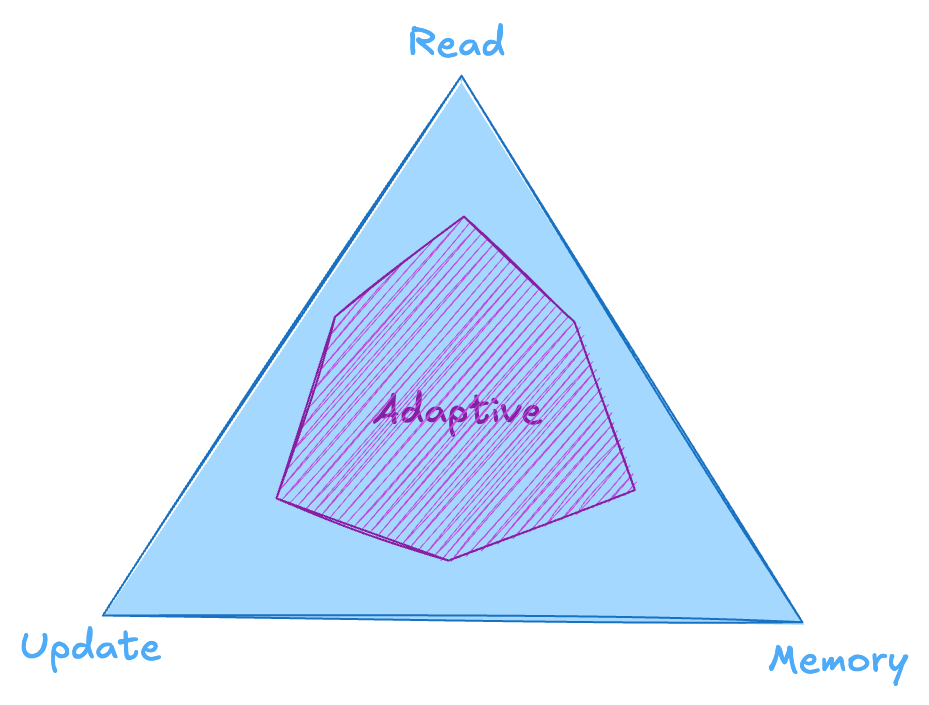
- Adaptive access methods: These structures include tunable parameters or are inherently adaptive, allowing them to adjust based on workload.
- Examples: Techniques like database cracking and adaptive merging use workload information to find an optimal balance among read, update, and memory costs.
Reference
Lastly, thank you for reading this post. For more awesome posts, you can explore my other articles here, and follow me on Github — amarlearning.
#rum conjecture #database design #data engineering #tech tradeoffs